

Cet article est extrait de la vidéo de SEO IS NO PICNIC n°3. Le fil rouge est simple : en SEO, les problèmes les plus intéressants sont souvent ceux qui résistent aux solutions évidentes. C’est là qu’un bon SEO black hat rex devient utile, non pas pour copier bêtement une manip, mais pour comprendre les signaux, les arbitrages et les limites de Google !
1. Quand une page ranke sans être indexée : le cas qui fait perdre patience
Le premier retour d’expérience concerne IFM, un site international avec une architecture par répertoires de langue et de pays. Le cas étudié porte sur une page française dédiée à une plateforme IoT, dupliquée en version belge francophone.
Sur le papier, tout semblait relativement propre :
- une page FR sur
/fr/fr/ - une page belge sur
/be/fr/ - des balises canoniques auto-référentes
- des balises hreflang cohérentes entre les deux variantes
Et pourtant, Google choisissait la page belge comme canonique, au lieu de la page française. Résultat : la page FR était considérée comme non indexée.

Jusque-là, rien de très exotique. En SEO international, dès qu’on mélange plusieurs répertoires avec une même langue, les cas de cannibalisation arrivent vite. Là où l’affaire devient franchement étrange, c’est que la page française commençait à se positionner sur le mot-clé cible alors même qu’elle n’était pas censée être indexée.
Pas d’impressions dans la Search Console. Pas de clics. Un site: qui ne remontait rien de propre. Et malgré ça, la page apparaissait dans les résultats. Là, on entre dans la zone grise qui rend un SEO black hat rex vraiment intéressant : le moment où les outils racontent une histoire, et la SERP en raconte une autre.
Le problème de fond : une architecture impossible à corriger proprement
Le vrai blocage venait de l’organisation interne du site. IFM France ne pilotait que son répertoire local. Le reste de l’infrastructure dépendait d’IFM Allemagne. Donc impossible de modifier la logique globale, impossible de toucher librement aux autres sections du domaine, impossible aussi d’imposer une refonte structurelle.
Autrement dit, le SEO devait réparer un problème dont il ne maîtrisait pas complètement les causes.
Tentative n°1 : renforcer les liens internes
Premier réflexe logique : envoyer davantage de liens internes vers la page française. L’idée était simple. Si la version FR reçoit plus de liens que la version belge, elle devrait finir par prendre le dessus.
Sauf qu’à chaque modification faite sur le site français, la logique de duplication répliquait aussi les changements sur les autres variantes. En clair, chaque nouveau lien FR créait son miroir côté Belgique.
Un mois de travail pour un résultat nul.
Tentative n°2 : différencier le contenu
Deuxième idée : rendre la page française plus explicitement française dans sa formulation. Si elle parle davantage de France, de service français, de marché français, elle devrait envoyer des signaux de pertinence plus forts que la version belge.
Sur le plan SEO, ça se tient. Sur le plan business, c’était plus compliqué. Le client ne voulait pas nuire à la filiale belge, qui restait une équipe sœur. Pas question de transformer la page en machine à exclure les voisins.
Tentative n°3 : acheter du trafic
Troisième piste : envoyer du trafic français sur la bonne page. Du trafic paid, du trafic pop, du trafic “fabriqué”. Le raisonnement était le même : si la page FR capte plus de signaux d’usage que la belge, peut-être que Google réévaluera le choix canonique.
Encore raté.
La page ne s’indexait toujours pas.
Tentative n°4 : manipuler le CTR depuis la SERP
Là, on bascule franchement dans le terrain du SEO black hat rex. La page étant visible dans la SERP malgré son statut bizarre, l’idée a été d’envoyer des clics depuis les résultats de recherche vers cette URL, avec des requêtes variées et une répartition paraissant naturelle.
Environ 50 clics par jour ont été envoyés sur la page.
Et là, nouvelle absurdité :
- la page gagnait des positions
- elle montait dans le top 10
- mais la Search Console restait vide
- et la page restait officiellement non indexée

Le genre de situation qui fait sérieusement douter de ce que l’on croit savoir sur l’indexation, le reporting et l’attribution des données.
Tentative n°5 : acheter des backlinks
Évidemment, des liens externes ont aussi été ajoutés. Propres, contextualisés, pensés pour pousser la page mère et quelques pages filles autour. Là encore, l’idée restait classique : si la page française devient plus populaire que sa concurrente belge, Google finira bien par réviser son arbitrage.
Non plus.
À ce stade, le problème n’était plus seulement un sujet client. C’était devenu une affaire personnelle.
2. Le détournement black hat qui a fini par marcher
Le point de bascule de ce SEO black hat rex, c’est l’usage détourné des balises canoniques à travers un autre site maîtrisé à 100 %.
IFM France disposait d’un petit site WordPress séparé, bien indexé, propre, avec un minimum d’autorité : IFM40. Et cette fois, l’équipe avait la main complète dessus.
L’idée a donc été la suivante :
- recréer la page Monitizer ou “Monéo” sur ce WordPress, le plus fidèlement possible
- garder une page propre, publiable, cohérente avec les enjeux de branding
- placer sur cette version WordPress une balise canonique pointant vers la page FR du site principal
En résumé :
- la page belge pointait vers elle-même
- la page FR pointait vers elle-même
- la copie WordPress pointait vers la page FR
La page française se retrouvait donc avec un signal canonique supplémentaire en sa faveur.

Et cette fois, ça a fonctionné. La page s’est indexée.
Est-ce que c’est uniquement la canonique externe qui a débloqué la situation ? Impossible à affirmer. Peut-être que c’est l’accumulation des signaux :
- liens internes
- trafic payé
- CTR artificiel
- backlinks
- et enfin cette canonique additionnelle
Corrélation n’est pas causalité. Mais dans ce SEO black hat rex, le seul vrai déclic observable a eu lieu après cette duplication contrôlée sur un site tiers.
Ce que ce cas enseigne vraiment
Il y a plusieurs leçons utiles ici.
- Le SEO international mal structuré coûte très cher. Quand on a une même langue répartie dans plusieurs répertoires, les risques de cannibalisation explosent.
- Les CCTLD restent plus simples à gérer quand l’objectif est de distinguer des marchés par pays.
- Les signaux de Google ne sont pas toujours lisibles dans les outils. Une page peut manifester des comportements de ranking alors que les interfaces semblent raconter l’inverse.
- Une solution tordue peut parfois débloquer une impasse réelle, mais elle ne remplace jamais une architecture saine.
Et surtout, ce cas rappelle qu’un bon SEO black hat rex n’est pas une glorification du black hat. C’est l’étude d’un contexte où des méthodes non orthodoxes apparaissent parce que les solutions propres ont été neutralisées par la technique, l’organisation ou la politique interne.
3. À quoi ressemble un contenu presque parfait en SEO
Après la descente aux enfers sur l’indexation, changement total d’ambiance. Deuxième sujet : un article pris comme référence absolue de ce qu’un contenu SEO ambitieux devrait essayer d’être.
L’exemple cité porte sur les facteurs de ranking en SEO local, une étude annuelle menée depuis des années par l’équipe de WhiteSpark autour de Darren Shaw. Ce type de contenu est l’exact opposé du contenu jetable. Et c’est précisément pour ça qu’il performe.
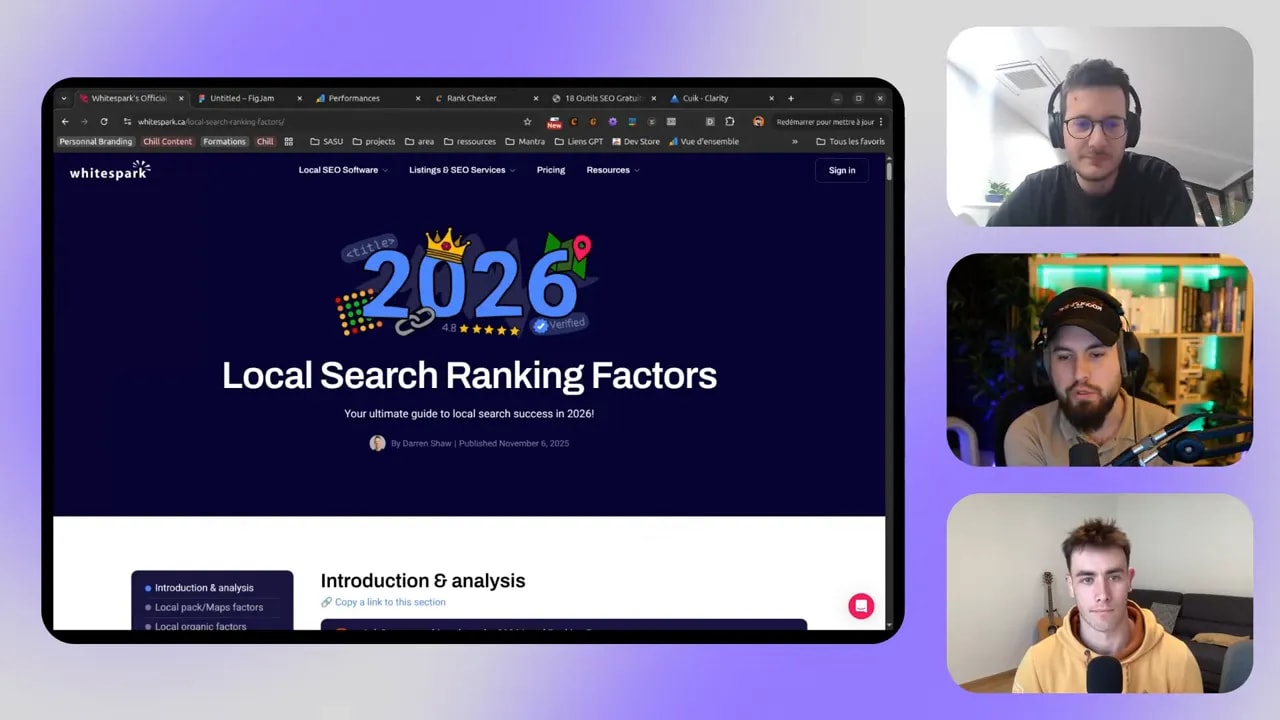
Pourquoi cette page est si forte
Le contenu cumule pratiquement tout ce qu’on aime voir sur une page éditoriale premium :
- un auteur identifiable
- une vraie profondeur de recherche
- des données originales
- des visuels pensés pour être partagés
- une structure facile à consommer
- des interactions à plusieurs niveaux
Dès le haut de page, tout est calibré :
- bio auteur visible
- table des matières sticky
- lead magnet intégré
- résumé audio de l’article
- appel à poser des questions sur Reddit
Ce dernier point est particulièrement malin. Proposer aux lecteurs d’aller échanger sur Reddit avec l’auteur, ce n’est pas seulement un gadget. C’est une manière de prolonger le contenu, de lui donner une vie communautaire, et d’envoyer un signal fort de légitimité.
Une page conçue pour tous les niveaux d’attention
Ce qui rend cette page si intelligente, c’est qu’elle laisse plusieurs façons de la consommer.
Quelqu’un peut :
- lire en détail
- scanner uniquement les H2
- écouter le résumé
- consulter les infographies
- ouvrir les tableaux de données qui l’intéressent
Ce n’est pas juste du “contenu long”. C’est du contenu modulaire.
Et ça change tout. Parce qu’un article de ce type n’oppresse pas avec 150 lignes de tableau dès l’arrivée. Les données sont disponibles, mais dans des blocs repliables. On garde ainsi la richesse sans sacrifier le confort de lecture.
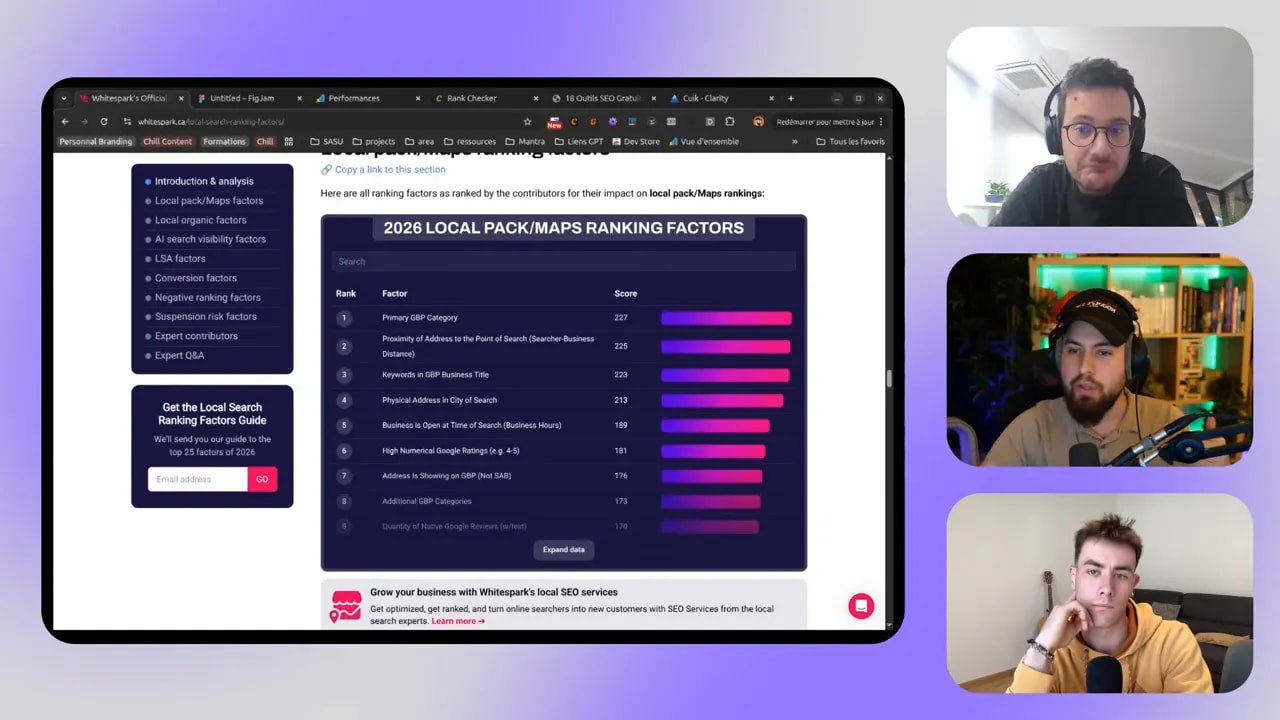
Le vrai différenciateur : la barrière à l’entrée par le design et la méthode
Le point le plus fort est peut-être là. Beaucoup de gens peuvent copier du texte. Beaucoup moins peuvent copier :
- une étude répétée sur plusieurs années
- des visualisations cohérentes
- une liste de dizaines d’experts mobilisés
- une FAQ alimentée par de multiples spécialistes
- une mise en forme pensée pour la diffusion sociale
C’est une vraie barrière à l’entrée. Même si quelqu’un pompe les facteurs, il ne récupère pas la crédibilité, ni la richesse du dispositif, ni l’expérience globale.
C’est exactement le genre de contenu qui donne envie d’être sauvegardé, cité, repris, transformé en posts LinkedIn, en newsletters, en carrousels, en PDF ou en conférences.
Autrement dit, le meilleur contenu SEO n’est pas seulement celui qui ranke. C’est celui qui produit des sous-contenus chez les autres.
La leçon pour les marques
La conclusion défendue ici est très claire : au lieu de produire 500 pages génériques, mieux vaut viser quelques contenus mémorables.
Des contenus :
- dont l’équipe est fière
- que l’on a envie d’envoyer dans une newsletter
- qui peuvent être cités par d’autres
- qui construisent l’image de marque autant que la visibilité SEO
Ce n’est pas qu’une logique éditoriale. C’est aussi une logique de signaux utilisateurs. Quand une page donne envie de cliquer, d’ouvrir, de replier, d’écouter, de partager, elle envoie naturellement des signaux d’engagement.
Encore une fois, ce SEO black hat rex montre un contraste utile : parfois, on doit forcer des signaux. Mais le vrai graal, c’est quand le contenu les génère de lui-même.
4. Le JS rendering peut ruiner le potentiel d’un site énorme
Troisième sujet, et pas des moindres : un site massif, avec des centaines de milliers d’URL, une forte autorité, des milliers de domaines référents… et un trafic organique ridiculement faible au regard de sa taille.
Le cas évoqué est celui d’un site orienté API et recettes, avec une volumétrie énorme, des dizaines de sitemaps de 50 000 URLs, et pourtant un rendement SEO catastrophique.
Le ratio est violent : beaucoup de popularité, très peu de trafic.
Quand on creuse, le problème semble venir du rendu JavaScript. Les pages se reconstruisent via des appels externes après chargement. Et dans certains cas, même avec rendu JS activé, Screaming Frog ne récupérait pas correctement le contenu. Difficile, dans ces conditions, d’imaginer Google le traiter proprement à grande échelle.
Le point important : Google peut rendre du JS, mais pas comme on aimerait
Il y a une idée fausse qui traîne encore : “Google sait gérer le JavaScript, donc ce n’est plus un problème.”
En réalité :
- Google peut exécuter du JS
- il ne le fait pas toujours
- il ne le fait pas forcément complètement
- et certainement pas avec la même constance sur toutes les pages d’un site massif
Quand le contenu n’existe vraiment qu’après une chaîne de scripts, d’appels externes et de reconstruction front, il suffit que ça coince à une étape pour que la page devienne quasi vide pour le moteur.
Les options techniques évoquées
Plusieurs stratégies ont été rappelées pour éviter ce genre d’impasse :
- SSR ou Server Side Rendering, où le HTML est généré côté serveur avant envoi
- SSG ou Static Site Generation, où les pages HTML sont construites à l’avance
- ISR, une logique hybride de régénération incrémentale
- prerendering pour servir une version pré-rendue aux bots
Le SSG a été particulièrement défendu pour les contextes où c’est possible. Une fois le build effectué, la page statique est instantanée, légère, propre, et ne dépend plus d’appels complexes en production.
Pour des sections éditoriales, des guides, des lexiques ou certaines catégories, c’est souvent une arme redoutable.
Le vrai warning
Le message à retenir est simple : un site peut avoir une énorme base de pages et rester assis sur une mine d’or SEO totalement sous-exploitée si son rendu n’est pas pensé pour l’exploration et l’indexation.
Le SEO black hat rex est amusant quand il raconte des manipulations de canonicals et de CTR. Mais parfois, le plus gros problème n’a rien de black hat. C’est juste une dette technique monstrueuse qui empêche Google de voir le contenu.
5. Ce que ces trois cas disent du SEO moderne
Pris séparément, ces exemples parlent d’indexation, de contenu et de rendu. Pris ensemble, ils racontent quelque chose de plus large.
Le SEO moderne repose sur trois couches qui doivent tenir en même temps :
- la couche technique, pour rendre les contenus accessibles, lisibles et indexables
- la couche éditoriale, pour produire une vraie valeur et mériter l’attention
- la couche comportementale, pour capter, garder et orienter l’engagement
Quand la technique échoue, on en arrive à des bricolages de type SEO black hat rex.
Quand l’éditorial est excellent, les signaux se fabriquent presque tout seuls.
Quand le rendu est mal pensé, même une énorme machine peut tourner dans le vide.
6. Les leçons les plus utiles à garder
Pour finir, voici la version condensée de ce qu’il fallait retenir.
- Une page peut se comporter de façon contre-intuitive dans Google. Les interfaces ne montrent pas toujours toute l’histoire.
- Les canonicals restent des signaux puissants, surtout quand ils s’additionnent dans un contexte de duplication.
- Le SEO international demande une architecture claire. Multiplier les variantes d’une même langue dans des répertoires différents est souvent une mauvaise idée.
- Le meilleur contenu n’est pas seulement informatif. Il est conçu pour être consommé, partagé, cité et difficile à reproduire.
- Le JavaScript n’est pas une excuse. Si Google ne voit pas le contenu de façon fiable, le potentiel SEO s’effondre.
- Les signaux utilisateurs comptent, qu’ils soient obtenus naturellement ou, dans certains cas limites, artificiellement poussés.
Un bon SEO black hat rex ne sert pas à dire “faites n’importe quoi”. Il sert à mieux voir où sont les vrais points de friction. Et parfois, ce regard un peu sale sur les mécaniques du moteur permet paradoxalement de mieux construire des stratégies beaucoup plus propres.
C’est peut-être ça, la vraie leçon. Le SEO récompense rarement les recettes magiques. En revanche, il réagit toujours à ceux qui comprennent les systèmes assez bien pour voir où ils cassent.