

Ce type d’architecture combine WordPress pour l’interface, N8N pour l’orchestration, une base documentaire pour les contenus de référence, et un modèle d’IA pour formuler les réponses. Résultat : un assistant plus utile, plus contrôlable et plus facile à mettre à jour qu’un modèle entraîné une fois pour toutes.
Voici un tutoriel complet, structuré étape par étape, pour comprendre et construire un workflow RAG WordPress N8N réaliste, avec les points de vigilance à ne pas négliger. Cet article est extrait de la vidéo de Infomaniak.
Step 1: comprendre ce qu’est un système RAG et pourquoi l’utiliser avec WordPress
RAG signifie Retrieval-Augmented Generation. En pratique, cela veut dire :
- récupérer des informations pertinentes dans une base de connaissances,
- transmettre ce contexte à un modèle de langage,
- laisser le modèle rédiger une réponse à partir des documents trouvés.
Un projet RAG WordPress N8N est particulièrement utile pour :
- répondre aux questions fréquentes sur un site e-commerce,
- assister les visiteurs à partir d’une documentation produit,
- fournir un support automatisé basé sur des procédures internes,
- réduire les réponses inventées en s’appuyant sur des sources choisies.
La différence avec un chatbot générique est essentielle. Sans RAG, le modèle répond selon ses connaissances générales. Avec un RAG, il peut s’appuyer sur vos propres fichiers.
Autre avantage : si la documentation change, il suffit de réindexer les documents. Il n’est pas nécessaire de réentraîner un modèle complet.

Pourquoi ne pas simplement entraîner un modèle sur ses documents ?
L’entraînement ou le fine-tuning peut sembler logique, mais pose vite un problème : dès qu’un document évolue, le modèle devient partiellement obsolète. Dans une architecture RAG WordPress N8N, les contenus restent séparés du modèle. Cela rend les mises à jour bien plus pratiques.
Step 2: préparer les briques nécessaires au projet RAG WordPress N8N
Avant de construire le workflow, il faut réunir les éléments de base.
- Un site WordPress qui affichera le widget de chat
- Une instance N8N déjà opérationnelle
- Une base documentaire avec les fichiers à exploiter
- Un accès API au service d’IA choisi
- Des jetons d’authentification pour les services connectés
Dans l’exemple présenté, les documents sont stockés dans un dossier dédié d’un espace de stockage en ligne. Ce détail est important : il vaut mieux cibler un dossier précis plutôt qu’exposer tout un espace documentaire à l’automatisation.
Le principe recommandé est donc le suivant :
- créer un dossier uniquement pour la base de connaissance du chatbot,
- y placer les fichiers qui doivent être consultables,
- exclure tout document sensible ou non destiné au support.
C’est une règle de sécurité simple, mais fondamentale dans tout projet RAG WordPress N8N.
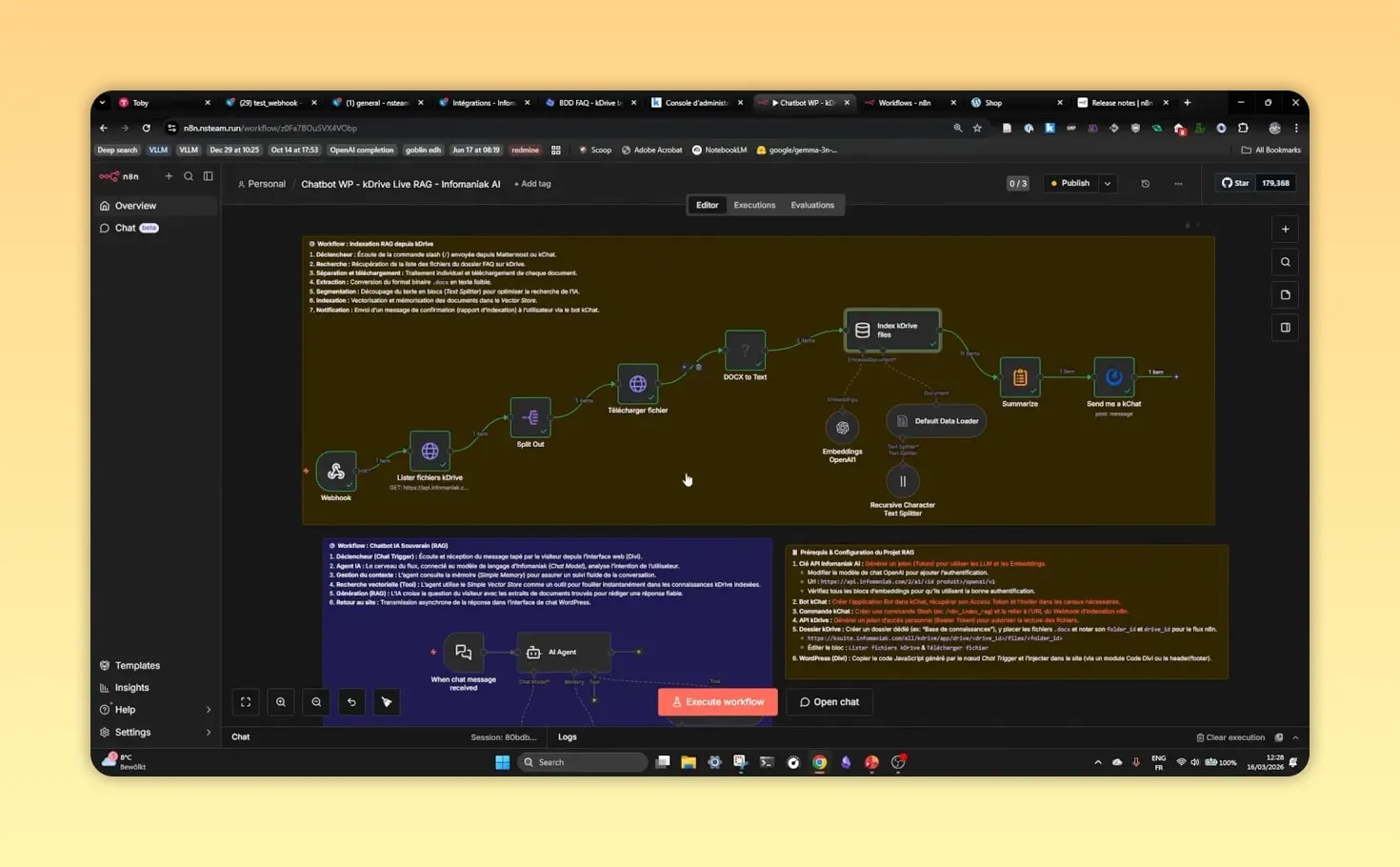
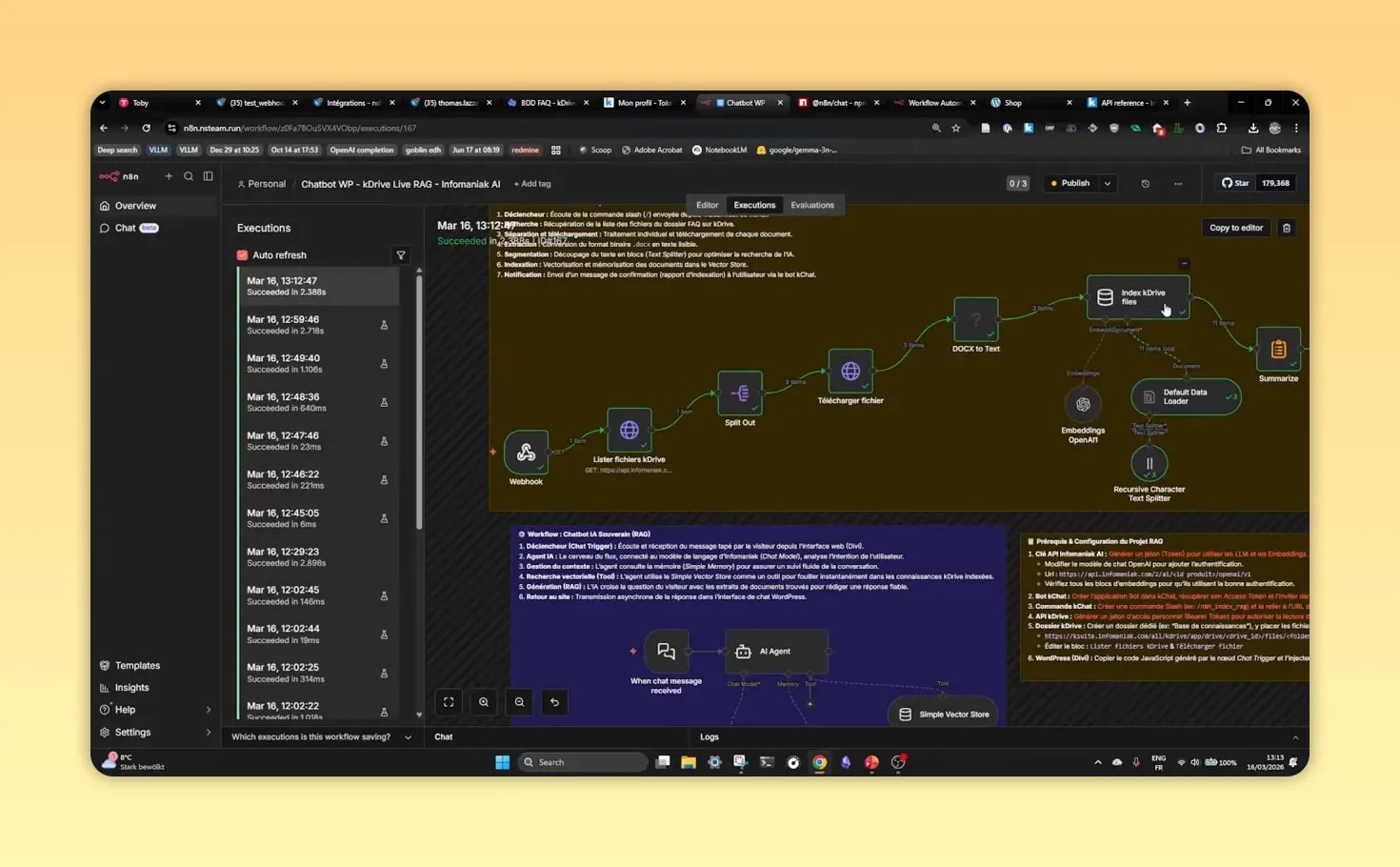
Step 3: comprendre le flux général du chatbot
Pour éviter de se perdre dans les nœuds N8N, il faut d’abord visualiser la logique globale.
Un workflow RAG WordPress N8N comprend généralement deux grandes parties :
- l’indexation des documents,
- la conversation avec l’utilisateur.
Partie 1 : indexation
- lister les fichiers du dossier documentaire,
- télécharger chaque fichier,
- extraire le texte,
- découper les contenus en segments,
- générer des embeddings,
- stocker les vecteurs dans une base adaptée.
Partie 2 : chat
- recevoir la question depuis WordPress,
- transformer la question en représentation vectorielle,
- retrouver les segments les plus proches,
- les envoyer au modèle de langage,
- renvoyer la réponse dans l’interface du chatbot.
Cette séparation est utile, car l’indexation n’a pas besoin d’être relancée à chaque question. Elle n’est à refaire qu’en cas de mise à jour des documents.
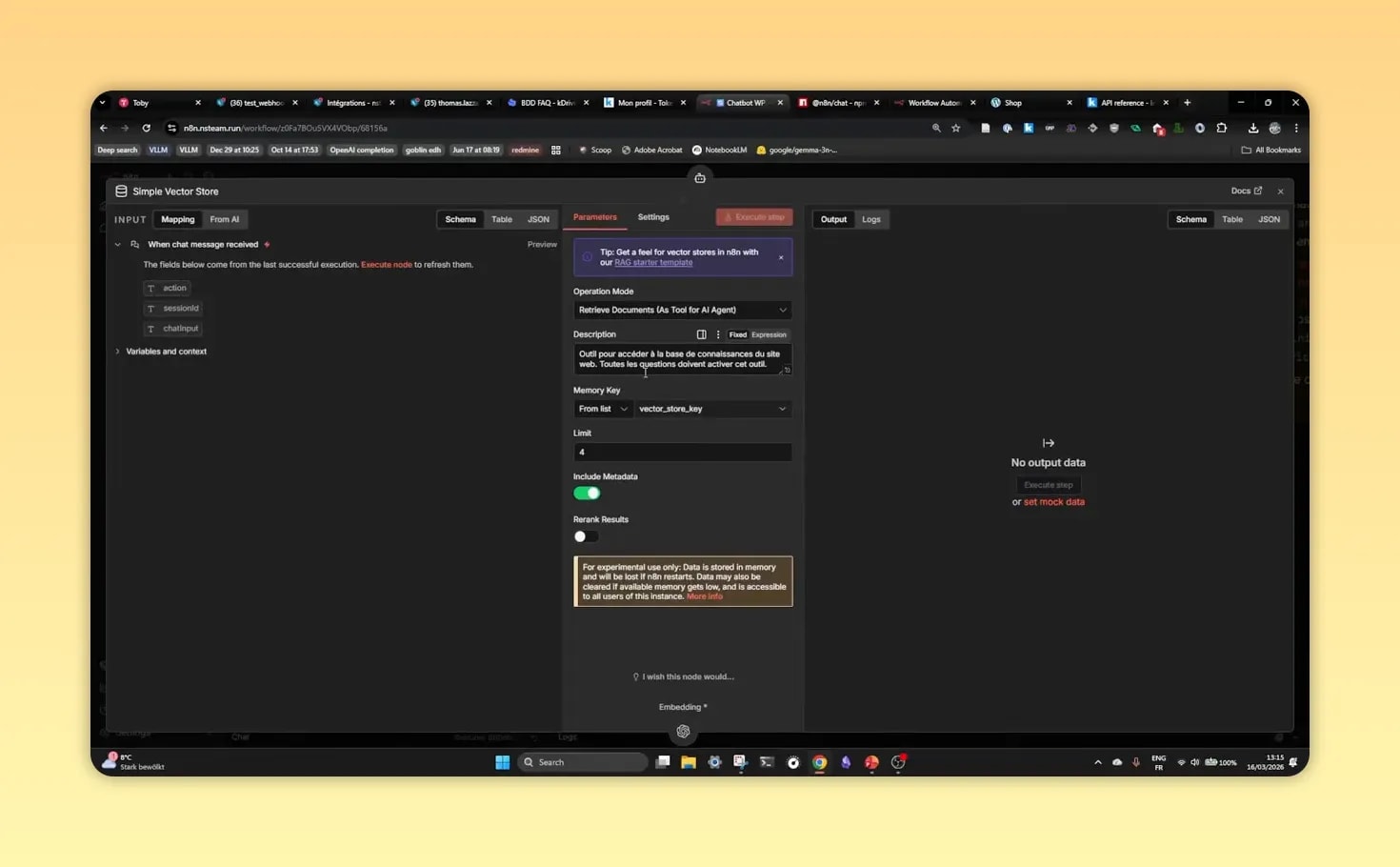
Step 4: indexer correctement les documents pour le RAG
L’indexation est le cœur technique du RAG WordPress N8N. Si elle est mal faite, le chatbot répondra mal, même avec un bon modèle.
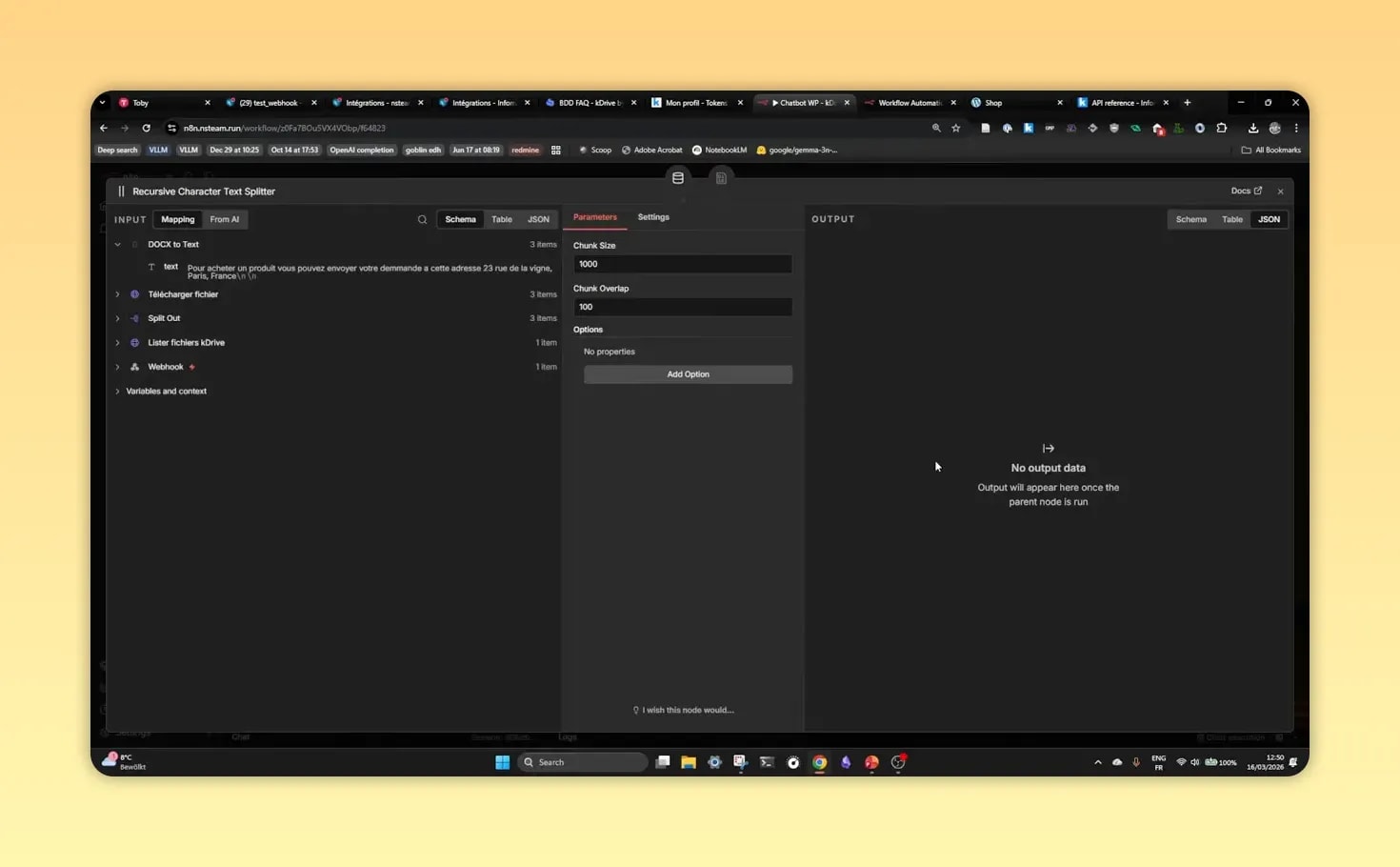
Découper les documents en morceaux
Un document complet est souvent trop long pour être traité efficacement d’un seul bloc. La bonne pratique consiste à le scinder en segments. Dans l’exemple montré, le découpage se fait par portions d’environ 1000 caractères, avec un léger chevauchement entre deux segments.
Ce chevauchement est utile pour éviter de perdre une information située à la frontière entre deux blocs.
Générer des embeddings
Un embedding est une représentation numérique d’un texte. Deux contenus proches sur le plan du sens auront des vecteurs proches. C’est ce qui permet une recherche sémantique plus intelligente qu’une simple recherche par mots-clés.
Dans un système RAG WordPress N8N, les embeddings servent à :
- vectoriser les segments documentaires,
- vectoriser la question de l’utilisateur,
- comparer les proximités sémantiques.
Stocker les vecteurs
Les vecteurs doivent être enregistrés dans une base pouvant servir de vector store. Une solution simple peut suffire pour une petite base documentaire. Pour de très gros volumes, une base vectorielle spécialisée devient plus pertinente.
Si la base de connaissance ne contient que quelques fichiers, une configuration légère reste généralement suffisante.
Step 5: récupérer les fichiers documentaires dans N8N
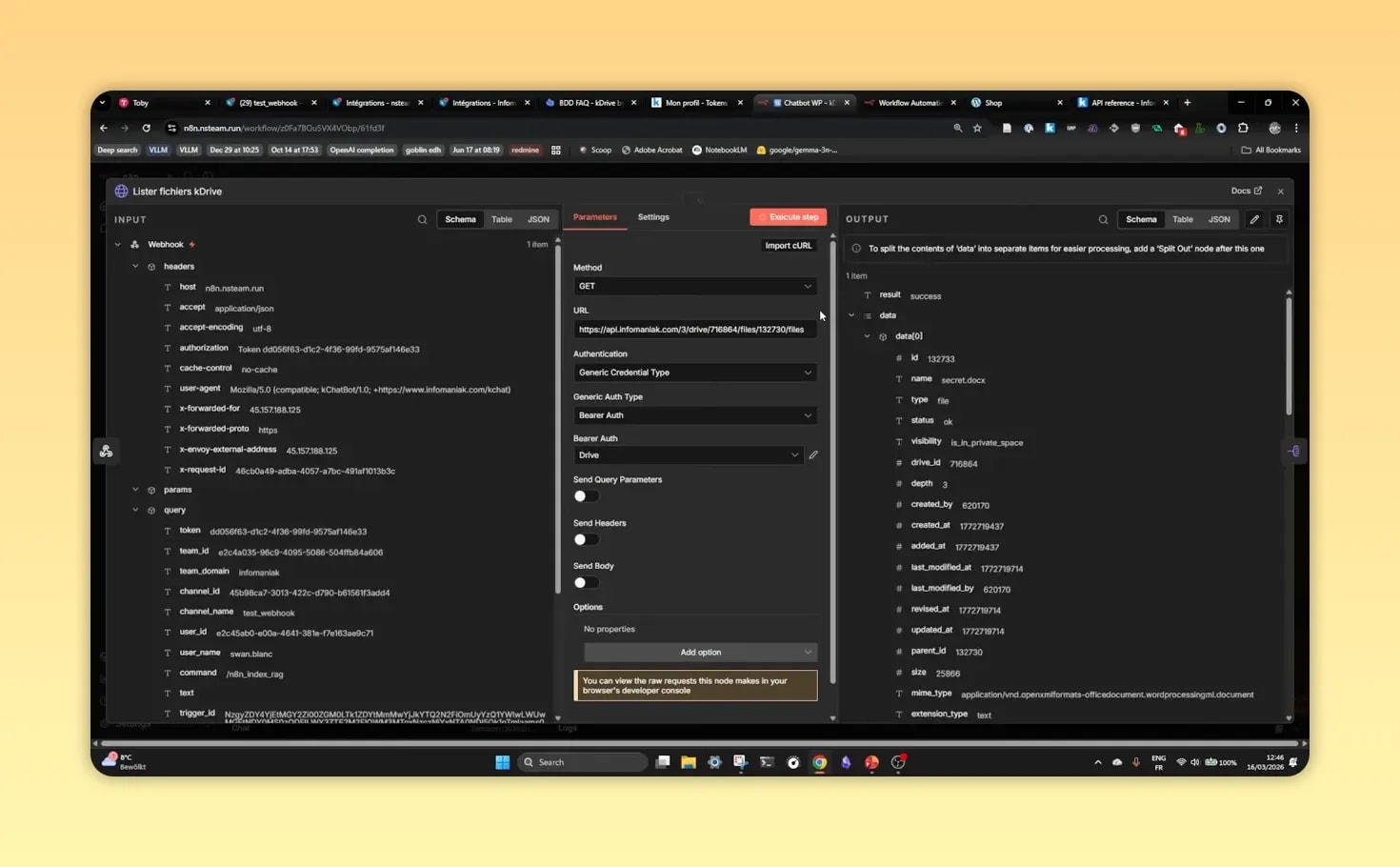
Une étape souvent sous-estimée dans un projet RAG WordPress N8N consiste à bien récupérer les fichiers source.
Le schéma classique est le suivant :
- appeler l’API du service de stockage pour lister les fichiers d’un dossier,
- traiter la liste des résultats,
- télécharger chaque fichier un par un.
Pourquoi faut-il parfois “splitter” la sortie ?
Quand l’API renvoie une liste de fichiers, N8N ne traite pas toujours automatiquement chaque élément comme une unité distincte. Il faut donc souvent utiliser un nœud de transformation pour convertir la réponse en plusieurs items séparés.
Sans cette étape, le téléchargement de chaque fichier risque de ne pas s’exécuter correctement fichier par fichier.
Ce point technique peut sembler mineur, mais il est très fréquent dans les workflows RAG WordPress N8N.
Step 6: convertir les fichiers en texte exploitable
Le modèle d’embedding ne travaille pas directement sur des fichiers bureautiques. Il a besoin de texte brut.
Dans le cas le plus simple, les fichiers DOCX peuvent être convertis en texte à l’aide d’un nœud dédié. Pour d’autres formats, il faut adapter la chaîne de traitement.
Formats à anticiper
- DOCX : conversion texte possible avec un nœud adapté
- TXT : exploitable directement
- PDF texte : nécessite un extracteur de texte PDF
- PDF image ou scan : nécessite une étape d’OCR
- Images : nécessitent une description ou une extraction multimodale
Un bon workflow RAG WordPress N8N doit donc intégrer une logique conditionnelle selon le type de fichier. Ce n’est pas indispensable pour une première version, mais c’est souvent nécessaire en production.
Step 7: connecter WordPress au chatbot N8N
Côté WordPress, le plus simple consiste à intégrer un script JavaScript qui affiche une interface de chat et communique avec un webhook N8N.
Le principe est le suivant :
- N8N génère un endpoint public pour recevoir les messages du chat,
- un script d’intégration est inséré dans WordPress,
- ce script utilise l’URL du webhook,
- les questions posées sur le site arrivent dans le workflow.
Dans un projet RAG WordPress N8N, cette partie est plus simple qu’elle n’en a l’air. L’essentiel est d’utiliser la bonne URL et de distinguer mode test et mode production. Beaucoup d’erreurs viennent de là.
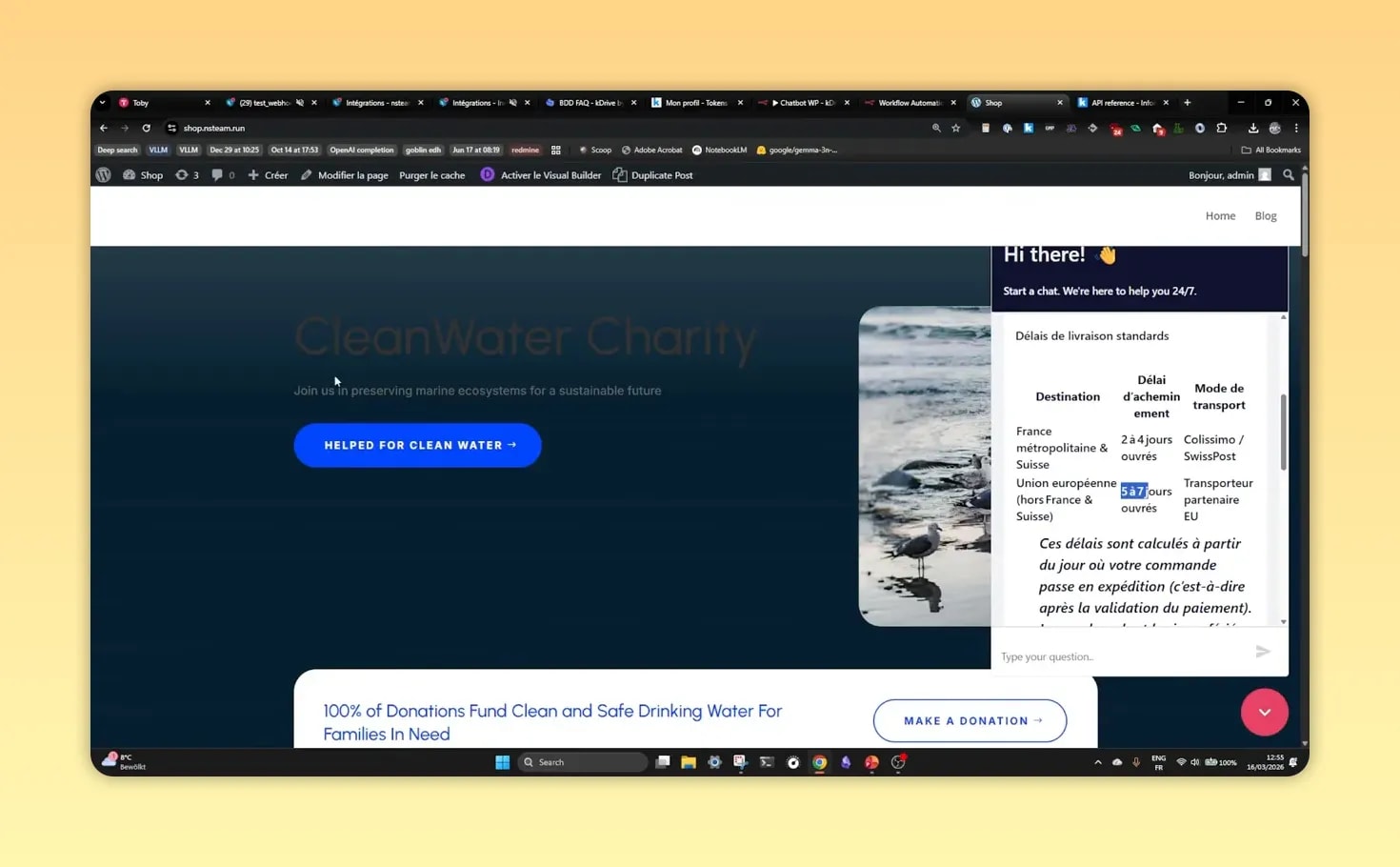
Où insérer le script dans WordPress ?
Plusieurs options existent selon le thème ou le constructeur de pages utilisé :
- dans un bloc code,
- dans un module HTML personnalisé,
- dans une zone d’injection de scripts du thème.
L’important est que le code soit chargé sur la page où le chatbot doit apparaître.
Step 8: configurer le modèle qui répond aux questions
Dans une architecture RAG WordPress N8N, il faut distinguer deux familles de modèles :
- le modèle d’embedding, utilisé pour la recherche sémantique,
- le modèle de génération, utilisé pour formuler la réponse finale.
Ce ne sont pas les mêmes rôles, et il ne faut pas les confondre.
Quel modèle choisir pour répondre ?
Pour un chatbot documentaire, il n’est pas forcément utile de choisir le modèle le plus coûteux ou le plus complexe. Si le RAG est bien construit, le modèle de génération a surtout besoin de reformuler clairement des informations déjà retrouvées dans les documents.
Autrement dit, la qualité de la base documentaire, du découpage et du retrieval compte souvent plus que le fait d’utiliser un modèle surdimensionné.
Step 9: ajouter des garde-fous contre les hallucinations
Un système RAG WordPress N8N réduit le risque d’hallucination, mais ne l’élimine pas totalement.
Pour améliorer la fiabilité, il faut agir à plusieurs niveaux.
1. Soigner le prompt système
Le modèle doit recevoir une consigne explicite, par exemple :
- répondre uniquement à partir des documents fournis,
- ne pas inventer si l’information manque,
- indiquer clairement qu’il ne sait pas si la réponse n’est pas trouvée.
2. Bien décrire l’outil de recherche
Si un agent IA dispose d’un outil d’accès à la base documentaire, sa description doit être claire. Cela l’aide à comprendre quand il doit interroger la connaissance interne.
3. Tester les questions ambiguës
Il faut vérifier le comportement du bot sur :
- des questions hors sujet,
- des formulations vagues,
- des demandes sans réponse dans la documentation.
Le bon comportement n’est pas de “faire plaisir”, mais de reconnaître l’absence d’information.
Step 10: sécuriser les accès et limiter les coûts
Un projet RAG WordPress N8N doit aussi être robuste sur les plans sécurité et budget.
Bonnes pratiques d’authentification
- créer un token par usage,
- limiter les scopes au strict nécessaire,
- conserver les jetons dans un gestionnaire de mots de passe,
- éviter les accès globaux inutiles.
Protéger les webhooks
Un webhook public peut être déclenché par n’importe qui s’il n’est pas protégé. Il faut donc vérifier l’origine des appels ou utiliser un mécanisme d’authentification adapté.
Prévenir les abus
Un chatbot exposé publiquement peut être spammé. Cela peut faire exploser les coûts API. Il faut envisager :
- du rate limiting,
- des restrictions d’usage,
- des quotas,
- une surveillance des exécutions.
C’est un sujet souvent oublié au lancement d’un RAG WordPress N8N, puis découvert trop tard.
Step 11: automatiser la réindexation des documents
Une base documentaire évolue. Si les fichiers changent, l’index doit être mis à jour.
Plusieurs approches sont possibles :
- réindexation manuelle via une commande ou un déclencheur simple,
- réindexation planifiée avec un trigger périodique,
- réindexation événementielle si le service source sait notifier un changement.
Quand il n’existe pas de notification native de modification, une tâche planifiée hebdomadaire ou quotidienne reste une solution efficace.
Pour une petite base, une réindexation complète est souvent suffisante. Pour une très grosse base, il faudra une logique plus fine afin de ne traiter que les changements.
Step 12: exploiter l’historique des conversations pour améliorer le bot
Un bon système RAG WordPress N8N ne s’arrête pas à la mise en ligne. Il s’améliore grâce aux conversations.
L’historique permet de repérer :
- les questions les plus fréquentes,
- les sujets mal couverts par la documentation,
- les formulations qui perturbent le retrieval,
- les réponses à enrichir ou reformuler.
Autre usage intéressant : envoyer périodiquement un résumé des échanges dans un canal d’équipe ou vers un autre workflow. Cela permet de transformer le chatbot en outil de veille client.
Step 13: adapter le workflow à d’autres sources que des documents
Une architecture RAG WordPress N8N ne se limite pas à des fichiers stockés dans un drive. Le même principe peut servir à indexer :
- des articles WordPress via l’API REST,
- une base de connaissances externe,
- des contenus d’outil documentaire,
- des emails récupérés via IMAP,
- d’autres applications accessibles par API.
Le pattern reste le même :
- récupérer les contenus,
- les transformer en texte,
- les découper,
- les vectoriser,
- les interroger au moment du chat.
C’est ce qui rend RAG WordPress N8N aussi flexible.
Step 14: éviter les erreurs les plus courantes
Voici les problèmes les plus fréquents lors de la mise en place.
Confondre URL de test et URL de production
Un workflow peut fonctionner en test puis sembler “cassé” en production, ou l’inverse, simplement parce que la mauvaise URL a été utilisée.
Indexer des documents non filtrés
Il faut toujours utiliser un dossier dédié. Sinon, le bot risque d’accéder à des fichiers non prévus.
Choisir un mauvais extracteur de texte
DOCX, PDF, images et scans ne se traitent pas de la même manière.
Négliger le prompt
Même avec un bon retrieval, un prompt flou peut produire des réponses inutiles ou trop affirmatives.
Oublier la supervision
Les logs et l’historique d’exécution sont précieux pour comprendre pourquoi une réponse a été générée.
Step 15: savoir quand cette architecture est adaptée
Le RAG WordPress N8N est un excellent choix si :
- les réponses doivent venir de documents spécifiques,
- la base de connaissance évolue régulièrement,
- il faut garder un bon niveau de contrôle,
- une équipe veut prototyper rapidement sans infrastructure lourde.
Ce n’est pas forcément la meilleure solution si :
- aucune documentation fiable n’existe,
- les données sont trop désorganisées,
- le besoin réel est plutôt un moteur de recherche classique,
- l’on attend du chatbot une expertise qu’aucun document interne ne couvre.
Conclusion
Mettre en place un RAG WordPress N8N permet de construire un chatbot utile, concret et orienté métier. Le vrai levier de qualité ne réside pas seulement dans le modèle d’IA, mais dans l’ensemble de la chaîne : sélection des documents, extraction du texte, découpage, recherche sémantique, prompt, sécurité et réindexation.
Pour démarrer proprement, le plus efficace est de :
- choisir un petit corpus de documents fiables,
- créer un premier workflow d’indexation simple,
- brancher le chat à WordPress,
- tester les cas limites,
- ajouter ensuite les raffinements nécessaires.
Un projet RAG WordPress N8N bien pensé peut ensuite évoluer vers d’autres usages : support client, recherche documentaire, synthèse d’échanges, FAQ dynamique ou indexation de contenus WordPress.
Le plus important reste toujours le même principe : donner au chatbot accès aux bonnes sources, et seulement aux bonnes sources.